Finally~ we proceed to the 2nd lesson of Machine Learning APIs!!!
I know previous lessons are kinda boring. 
Now we will jump into more intereting practical stuffs.
We will start with the Cloud Vision API's text detection method to make use of Optical Character Recognition (OCR) to extract text from images.
Then we will learn how to translate that text with the Translation API and analyze it with the Natural Language API.
Sounds fun and strange right ?!
Waiting no more. Let's start!
Open Google Cloud Platform ( follow the step in A Tour of Qwiklabs and Google Cloud )
Activate Cloud Shell
Cloud Shell is a virtual machine that is loaded with development tools.
When you are connected, you are already authenticated, and the project is set to your PROJECTID.
Create an API Key
Create an API key under APIs & services in Google Cloud Platform.
Run the following in Cloud Shell, replacing <your_api_key> with the key you just copied.
export API_KEY=<YOUR_API_KEY>
Create a Cloud Storage bucket
Go Storage in Google Cloud Platform and give your bucket a globally unique name.
Upload an image to your bucket
We use this image as a sample.
Once this image is uploaded, set the permission to PUBLIC. So we'll now see that the file has public access.
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/sign.jpg"
}
},
"features": [
{
"type": "TEXT_DETECTION",
"maxResults": 10
}
]
}
]
}
We're going to use the TEXT_DETECTION feature of the Vision API. This will run optical character recognition (OCR) on the image to extract text.
curl -s -X POST -H "Content-Type: application/json" --data-binary @ocr-request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
The first part of the response should look like the following: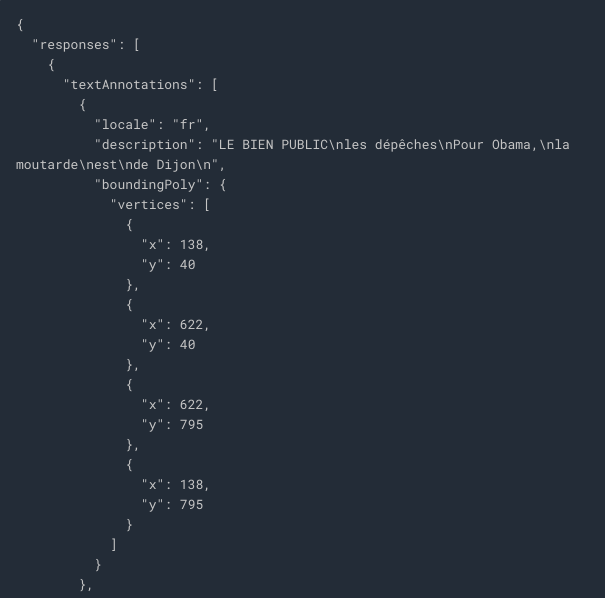
textAnnotations is the entire block of text the API found in the image. This includes the language code (in this case fr for French), a string of the text, and a bounding box indicating where the text was found in our image.
Run the following curl command to save the response to an ocr-response.json file so it can be referenced later:
curl -s -X POST -H "Content-Type: application/json" --data-binary @ocr-request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY} -o ocr-response.json
{
"q": "your_text_here", // will pass this string to translate
"target": "en"
}
Extract the image text from the previous step and copy it into a new translation-request.json:
STR=$(jq .responses[0].textAnnotations[0].description ocr-response.json) && STR="${STR//\"}" && sed -i "s|your_text_here|$STR|g" translation-request.json
Call the Translation API and copy the response into translation-response.json file:
curl -s -X POST -H "Content-Type: application/json" --data-binary @translation-request.json https://translation.googleapis.com/language/translate/v2?key=${API_KEY} -o translation-response.json
Inspect the file with the Translation API response: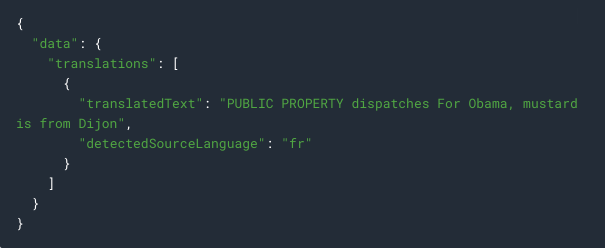
translatedText contains the resulting translation, and detectedSourceLanguage is fr, the ISO language code for French.
To set up the API request, create a nl-request.json file with the following:
{
"document": {
"type": "PLAIN_TEXT", // support PLAIN_TEXT or HTML
"content": "your_text_here" // text to send to the Natural Language API for analysis
},
"encodingType": "UTF8" // tells the API which type of text encoding to use when processing the text
}
Copy the translated text into the content block of the Natural Language API request:
STR=$(jq .data.translations[0].translatedText translation-response.json) && STR="${STR//\"}" && sed -i "s|your_text_here|$STR|g" nl-request.json
The nl-request.json file now contains the translated English text from the original image.
Call the analyzeEntities endpoint of the Natural Language API with this curl request:
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @nl-request.json
The following response you can see the entities the Natural Language API found: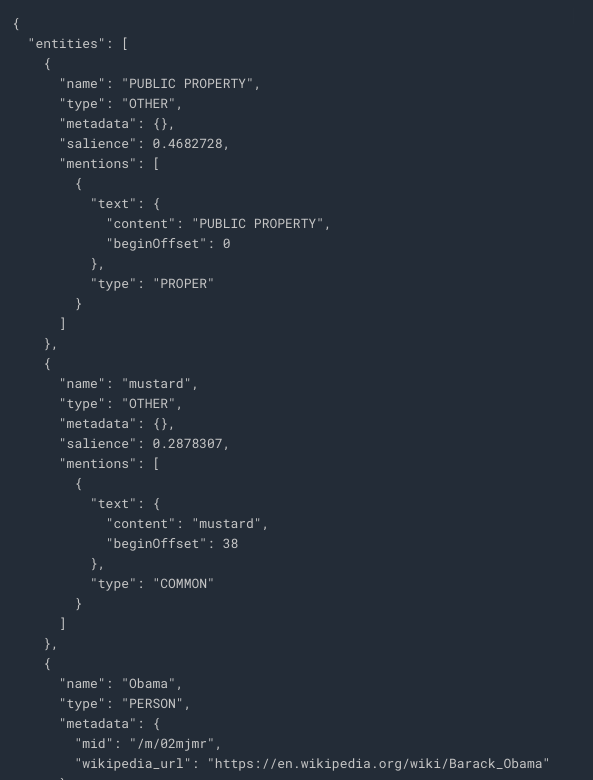
For entities that have a wikipedia page, the API provides metadata including the URL of that page along with the entity's mid. The mid is an ID that maps to this entity in Google's Knowledge Graph.
For all entities, the Natural Language API tells us the places it appeared in the text (mentions), the type of entity, and salience (a [0,1] range indicating how important the entity is to the text as a whole).
Ha~ another long article 
But I think is more interesting than the previous one as it has more hands-on practice this time.
Hope you a fun time 

